Regular expressions from the ground up
Regular expressions are an interesting topic in computer science where theory meets applications, because results in formal language theory have allowed us to construct regular expression processors that quickly and easily filter input strings. In this post, I will explore these results to create a toy processor in Haskell.
But first, a little theory. Regular expressions are simply names given to sets of strings, called regular sets. Given some alphabet Σ, the following rules are used to compose these names:
- ∅ denotes ∅, the empty set of strings
- ε (the regex, not string) denotes {ε}, the set of empty strings
- If a ∈ Σ, a denotes {a}, the set of strings of the single character a
The following rules use two arbitrary regular expressions r₁ and r₂.
- r₁ r₂ denotes the set of concatenations of all strings in the sets denoted by either expression
- r₁ | r₂ denotes the union of the sets denoted by either expression
- r₁* denotes the set of finite concatenations of every string in the set denoted by said expression, including ε
Repeated applications of these rules allow us to construct expressions like (a|b)*c, which denotes the set {c, ac, bc, aac, abc, bac, bbc, …}. We can start writing the equivalent code, but we have to make a few modifications to the symbols so that Haskell will accept them.
module Text.Regex.Core where
-- | The Regex ADT
data Regex σ
-- | ∅
= Φ
-- | ε
| Λ
-- | Literal
| (:#) σ
-- | Concatenation
| (Regex σ) :⧺ (Regex σ)
-- | Alternation
| (Regex σ) :+ (Regex σ)
-- | Kleene star
| (:*) (Regex σ)Thus, we say any given string matches a regular expression if it is a member of the generated regular set. For example, one could write a regular expression that denotes the set of valid email addresses and use it to reject invalid usernames. For simplicity, we’ll refer to patterns as regular expressions that act on the alphabet of Unicode characters, although we have defined regexes to operate on any given alphabet.
{-# LANGUAGE OverloadedStrings, UnicodeSyntax #-}
module Text.Regex (matches) where
import Text.Regex.Core
-- | Synonym for regex strings
type Pattern = Regex Char
-- | Determines whether an input string
-- matches against a regular expression
matches ∷ String → Pattern → Bool
matches = undefined -- ???Just by going off of these rules, we could create a processor that just figures out the denoted regular set and searches through it for the input string. However, since the 6th rule allows us to generate infinite sets, searching through it would take an unreasonable amount of time. So let’s take a brief interlude with finite automata.
For those who do not know what deterministic finite automata (DFAs) or nondeterministic finite automata (NFAs) are:
(Copied and pasted from my first post) A DFA is a 5-tuple (Q, Σ, δ, q₀, F) where Q is a set of states, Σ is a formal alphabet, δ: Q × Σ → Q is a transition function, q₀ is a start state in Q, and F is a set of accept states in Q. Given this information, we can figure out if a given automata “accepts” an input string built from the Σ by taking the first character in the string, applying the transition function on it and the initial state, and retrieving the returned state. Then, we take the next character and apply the transition function again on it and the aforementioned returned state, and so on. Thus, we transition from state to state until we reach the end of the string. If the final transitioned state is in the set of accept states, then the automata accepts this string. Otherwise, it rejects it. The Wikipedia article on DFAs contains examples as well as pretty state diagrams if you want a more in-depth explanation. Writing a DFA in Haskell involves (1) writing out the tuple as a data type and (2) defining the accept function, which is a traditional list fold. To elaborate, we are essentially running through the list of input symbols starting from the start state and stepping with the transition function. At the end, we just check whether the state we ended on is a final state.
{-# LANGUAGE UnicodeSyntax, RecordWildCards #-}
module Text.Regex.DFA where
import Data.Set (Set)
import Data.Set.Unicode ((∈))
-- | Represents a deterministic finite automaton (DFA)
data DFA q σ = DFA {
-- | The transition function
δ ∷ q → σ → q,
-- | The initial state
q₀ ∷ q,
-- | The set of final states
f ∷ Set q
}
-- | Determines whether a DFA accepts an input string
accepts ∷ Ord q ⇒ DFA q σ → [σ] → Bool
DFA{..} `accepts` s = foldl δ q₀ s ∈ fThe complexity of the accept function is linear with respect to the length of the input string, which is not bad in my opinion.
NFAs are similar to DFAs in that they too follow the state transition idea, but they are nondeterministic, so the transition function can return a set of possible states for transitioning, so it becomes δ: Q × Σ → 2Q. Thus, we can consider the execution logic of an NFA as a decision tree, where every transition opens up a set of new possible states. Thus, an NFA accepts an input string if there exists a path within this tree from the start state to a final state. The Wikipedia article on NFAs is quite helpful as well. To encode this logic in Haskell, we can define an NFA data structure and define the accept function as a monadic fold. In short, the list monad allows us to model nondeterministic computations, so we can fold on the input with the transition function and the start state, which will generate a set of end states for every possible path through the decision tree. With the set of end states, we can just test whether there was a path with a final state using the any function. This post goes into more depth on why the list monad is so awesome.
{-# LANGUAGE UnicodeSyntax, RecordWildCards, LambdaCase #-}
module Text.Regex.NFA where
import Prelude hiding (map, null, filter)
import qualified Prelude as P
import Prelude.Unicode (ℤ, (≡), (∨), (∧), (∘))
import Data.Ord.Unicode ((≤), (≥))
import Data.Set (Set, fromList, toList,
toAscList, singleton, unions,
map, null, filter, insert, delete)
import Data.Set.Unicode ((∅), (∋), (∩), (∪), (∖))
import Control.Monad (foldM)
import Data.List (subsequences)
import Text.Regex.Core
import Text.Regex.DFA (DFA(..))
-- | Represents a nondeterministic finite automaton (NFA)
data NFA q σ = NFA {
-- | The transition function
δ ∷ q → σ → Set q,
-- | The initial state
q₀ ∷ q,
-- | The set of final states
f ∷ Set q
}
-- | Determines whether an NFA accepts an input string
accepts ∷ Ord q ⇒ NFA q σ → [σ] → Bool
accepts NFA{..} = any ((∋)f) ∘ foldM ((toList ∘) ∘ δ) q₀Since this algorithm requires us to generate every possible path, the complexity is exponential with respect to the length of the input string.
If you noticed, DFAs and NFAs look awfully similar to regular expressions in terms of accepting/matching and rejecting strings, which leads us to Kleene’s theorem, which states that the class of regular languages is equal to the class of languages recognized by finite automata. The specific conversion is described by Thompson’s construction, a set of 6 rules that allows us to convert regular expressions to nondeterministic finite automata with ε-transitions (NFA-ε), NFAs that allow transitions without consuming input characters, since we can always append ε to the input and have the same string.
Since I lack the ability to draw, you should look at the diagrams of the automata here.
Given a regular expression r, we can generate the equivalent NFA-ε by case analysis on r:
- ∅ generates an empty automaton
- ε generates an automaton with a start state having an ε-transition to a final state
- A character a generates the same automaton as above except with a transition on a
- r₁ r₂ generates an automaton that runs through each corresponding automaton in order
- r₁ | r₂ genereates an automaton that can dispatch to either corresponding automaton of each expression using ε-transitions
- r₁* generates an automaton that “wedges” the internal automaton between a series of ε-transitions such that input can be repeatedly consumed (as well as not at all)
Coding this involves a bit of work, because we need (1) some way of encoding ε into the input, (2) a way to mentally convert these rules into actual automata, and (3) a way to procedurally generate states in cases where we combine automata. We achieve the first by making the input Maybe σ, allowing ε to be Nothing. Thus, we can do case analysis on the input symbol in the transition function whenever necessary. The second is achieved by staring at the Wikipedia diagrams for a while. The third requires a bit of cleverness–we could use a custom data structure here, but why not use the set of integers? After all, there exists an infinite amount of them, and creating states for the first three types of regular expression is trivial using the constants 0 and 1. But how will we create unique states in the last three cases? For example, a 5th case expression composed of character literals will have clashing state names, assuming we used those constant names. To fix this, we’ll need a smart scheme that will allow us to easily rename these states and construct a transition function without much hassle.
We will preserve a combination of Thompson’s invariants and what I will refer to as the densely ordered invariant.
While doing so, we will need to preserve the following invariants; consider the generated automaton M.
- M’s initial state must not have any in-transitions
- M has at most one final state which doesn’t have any out-transitions
Now for the densely ordered invariant:
- Adjacent states (i.e. states one transition apart) differ by at most and at least 1 (density)
- States on the left and top are less than the states on the right and bottom (order)
What do these mean? Let’s construct automata for all cases to find out.
Φ is pretty easy; since it accepts nothing, there is only an initial state but no final state and no transitions. All invariants are preserved since there are no other states for comparison.
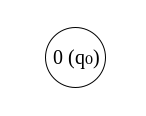
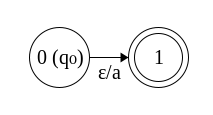
Λ and (:#) a are fairly trivial as well. Since there are two states however, we have to make sure that we only mark the second one as final, that the first state has no in-transitions, and that the final state has no out-transitions. Furthermore, since they’re adjacent, they can only differ by 1, and they have to be arranged in ascending order. This works by labeling the first state 0 and the second as 1.
r₁ :⧺ r₂ is harder. We replace the initial state of the second automaton with the final state of the first automaton, combining them. Although the constituent automata may obey the invariants, combining them directly will violate the invariants for the new automaton, so we have to do some smart renaming. Consider the following new automaton without any renaming, where the tilde represents omitted intermediate states.
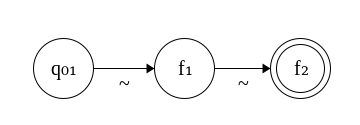
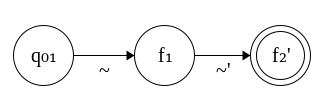
According to the 4th clause, states need to be in ascending order from left to right. We know q₀₁ < … < f₁, but we can’t say for sure that f₁ < … < f₂, so this is wrong. We need to increment every state in the second automaton by a quantity d that not only ensures that every state is greater than the states of the first automaton (obeying clause 4), but also that f₁ and q₀₂ + 1 (the second state in the second automaton) differ by exactly 1, preserving density. Thus, letting d = f₁ - q₀₂ works because (q₀₂ + 1) + (f₁ - q₀₂) = f₁ + 1, as desired. Since the old states of the second automaton were dense from the beginning, they will remain dense because they are scaled by the same quantity, and the entire automaton increases as we read left to right.
The new transition function on q and s will return δ₁ q s if q ≥ q₀₁ ∧ q < f₁. We don’t include f₁ because by clause 2, any transitions out of this state must be processed by the second automaton. So, if q ≥ f₁ ∧ q ≤ f₂’, then it dispatches to the second transition function, but it must be passed q - d since it does not recognize the new system, and the result must be scaled up by d to stay consistent. We now see that the invariants are necessary to ensure no name clashing as well as a way for the new transition function to dispatch to its constituent functions. The corrected automaton is now as follows, where primed states have been incremented.
r₁ :+ r₂ is probably the hardest case because we have new states to add, as well as the “top” and “bottom” case. If we were to combine then naively using Thompson’s construction, we would end up with the following automaton.
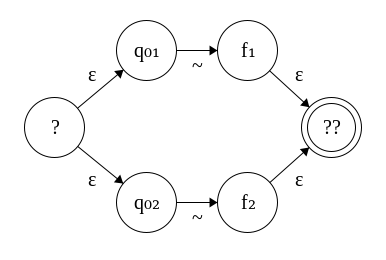
According to clause 4, we want ? < q₀₁ < … < f₁ < q₀₂ < … < f₂ < ??. The problem is, we don’t know if … < f₁ < q₀₂ < …, so we have to rename the states in the bottom automaton. We need to preserve density, so given some quantity d, f₁ and q₀₂’ = q₀₂ + d must differ by exactly 1. Letting d = f₁ - q₀₂ + 1 works, because q₀₂’ = q₀₂ + d = q₀₂ + f₁ - q₀₂ + 1 = f₁ + 1 as desired. Scaling up the rest of the states after q₀₂ by d will also work once again, as they were dense previously. Finally, we need the states at the left and right extremes of this new automaton to be the minimum and maximum relative to the existing states. Letting ? = q₀₁ - 1 and ?? = f₂’ + 1 works and preserves density as well. The transition function behaves similarly to the concatenation case, except now it must consider the special cases of ε-transitions separately. The corrected automaton is shown below.
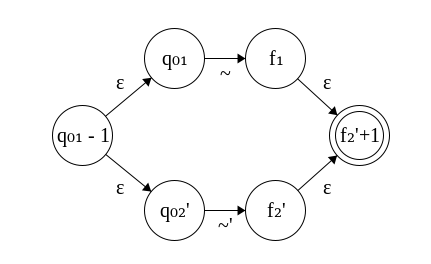
(:*) r is easier since we’re only dealing with one automaton. No renaming has to be done, but since we have a new state on the left and right of the old automaton, they have to differ exactly by 1 with respect to the old start and final states. The resultant transition function will dispatch to the old one if it is within range of the old states, and will handle special cases separately.
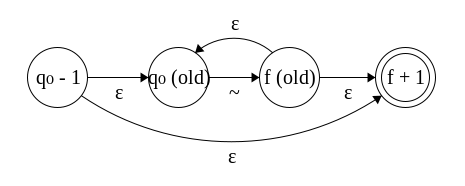
Now, we can directly translate this algorithm into Haskell code.
-- | Represents an NFA-ε
type NFAε q σ = NFA q (Maybe σ)
-- | A special NFA that keeps track of all of its states
type RNFA q σ = (Set q, NFA q σ)
-- | Analogous to the RNFA, but for NFA-ε
type RNFAε q σ = (Set q, NFAε q σ)
-- | Converts a regex to an NFA-ε that obeys the following invariants
-- * Generated automata have exactly one final state
-- * Final states are not co-accessible from other states
-- * States are dense and ordered
toNFAε ∷ Eq σ ⇒ Regex σ → RNFAε ℤ σ
toNFAε = let zero = singleton 0
one = singleton 1
bin = fromList [0, 1]
hd = head ∘ toList in \case
Φ → (zero, NFA (\_ _ → (∅)) 0 (∅))
Λ → (bin, NFA δ 0 one) where
δ 0 Nothing = one
δ _ _ = (∅)
(:#) a → (bin, NFA δ 0 one) where
δ 0 (Just c) = if c ≡ a then one else (∅)
δ _ _ = (∅)
r₁ :⧺ r₂ → (q', NFA δ' q₀₁ $ singleton f₂') where
(q₁, NFA {q₀ = q₀₁, δ = δ₁, f = f₁}) = toNFAε r₁
(q₂, NFA {q₀ = q₀₂, δ = δ₂, f = f₂}) = toNFAε r₂
f₁' = hd f₁
d = f₁' - q₀₂
(f₂', q₂') = (hd f₂ + d, map (+ d) $ delete q₀₂ q₂)
q' = q₁ ∪ q₂'
δ' q s | q ≥ q₀₁ ∧ q < f₁' = δ₁ q s
| q ≥ f₁' ∧ q ≤ f₂' = map (+ d) $ δ₂ (q - d) s
| otherwise = (∅)
r₁ :+ r₂ → (q', NFA δ' q₀' f') where
(q₁, NFA {q₀ = q₀₁, δ = δ₁, f = f₁}) = toNFAε r₁
(q₂, NFA {q₀ = q₀₂, δ = δ₂, f = f₂}) = toNFAε r₂
f₁' = hd f₁
d = f₁' - q₀₂ + 1
(q₀', f') = (q₀₁ - 1, singleton $ f₂' + 1)
(f₂', q₂') = (hd f₂ + d, map (+ d) q₂)
(q₀₂', q') = (q₀₂ + d, insert q₀' $ q₁ ∪ q₂' ∪ f')
δ' q s | q ≡ q₀' ∧ s ≡ Nothing = fromList [q₀₁, q₀₂']
| (q ≡ f₁' ∨ q ≡ f₂') ∧ s ≡ Nothing = f'
| q ≥ q₀₁ ∧ q ≤ f₁' = δ₁ q s
| q ≥ q₀₂' ∧ q ≤ f₂' = map (+ d) $ δ₂ (q - d) s
| otherwise = (∅)
(:*) r → (q', NFA δ' q₀' f') where
(q, NFA{..}) = toNFAε r
(q₀', f₀) = (q₀ - 1, hd f)
f' = singleton $ f₀ + 1
q' = insert q₀' $ q ∪ f'
δ' q s | (q ≡ q₀' ∨ q ≡ f₀) ∧ s ≡ Nothing = singleton q₀ ∪ f'
| otherwise = δ q sNFA-ε are pretty useless on their own because we’d have to litter the input with Nothings for it to execute properly, so let’s strip out the ε-transitions to get a good old-fashioned NFA. This involves finding the transitive closure of the set of states with respect to the transition function acting on Nothing, which is essentially all reachable states from a given state after the ε-transition. We achieve this by repeatedly applying the transition function until we’re left with the same set of states. From this, we can have the new transition function generate and return the closure on incoming states, while the new set of final states are simply reachable old final states from the closure.
-- | Converts an NFA-ε to a regular NFA
toNFA ∷ Ord q ⇒ RNFAε q σ → RNFA q σ
toNFA (q, NFA{..}) = (q, NFA δ' q₀ f') where
δ' q' s = unions $ toList $ map (flip δ $ Just s) $ εs $ singleton q'
f' = filter (not ∘ null ∘ (∩) f ∘ εs ∘ singleton) q
εs = transCl (flip δ $ Nothing)
transCl f set | null diff = set
| otherwise = transCl f $ set ∪ diff
where diff = (unions $ toList $ map f set) ∖ setEven though we could stop and just check whether the NFA accepts the input string, we can convert it to a DFA using the powerset construction, so we don’t have to deal with the exponential time required to check whether the automaton accepts the string. This involves generating a set of new states from the powerset of original states, where each subset is a new state. The subset of subsets that contain the original final states are the new final states. Finally, we can construct the new delta function by applying the old delta function to every state within the incoming set of states, producing the next subset for transitioning. Effectively, we have expanded the states with nondeterministic transitions into auxiliary states that handle each case separately. Inspired by this post.
-- | Converts an NFA to a DFA
toDFA ∷ Ord q ⇒ RNFA q σ → DFA (Set q) σ
toDFA (q, NFA{..}) = DFA δ' (singleton q₀) f' where
δ' q'' s = unions $ toList $ map (flip δ s) q''
q' = fromList $ P.map fromList $ subsequences $ toAscList q
f' = filter (not ∘ null ∘ (∩) f) q'This construction reduces the complexity of the accept function from exponential to linear time at the cost of an exponential increase in number of states (hence the name powerset). However, that’s a pretty acceptable tradeoff considering that we generally have a lot of RAM to go around.
Now that the conversion from regular expression to DFA is complete, we can tie it all together. Plus, it’d probably be good to have a parser so that we can write regular expressions directly instead of having to deal with the clunky Regex ADT.
{-# LANGUAGE UnicodeSyntax, FlexibleInstances #-}
module Text.Regex.Parser () where
import GHC.Exts (IsString(..))
import Text.Parsec.Expr (Assoc(..), Operator(..),
buildExpressionParser)
import Text.ParserCombinators.Parsec (Parser, parse, oneOf,
noneOf, choice, eof)
import Text.ParserCombinators.Parsec.Language (emptyDef)
import qualified Text.ParserCombinators.Parsec.Token as T
import Control.Applicative ((<$>), (<*))
import Text.Regex.Core
regexLang = emptyDef {
T.identStart = T.identLetter regexLang,
T.identLetter = noneOf "|*()",
T.opLetter = oneOf "|*",
T.reservedOpNames = ["|", "*"],
T.reservedNames = ["∅", "ε"]
}
lexer = T.makeTokenParser regexLang
char = T.identLetter regexLang
resOp = T.reservedOp lexer
resName = T.reserved lexer
parens = T.parens lexer
regex = buildExpressionParser
[ [op Postfix "*" (:*)]
, [ Infix (return (:⧺)) AssocLeft]
, [op Infix "|" (:+) AssocLeft]
] term where
term = choice [parens regex, res "∅" Φ,
res "ε" Λ, (:#) <$> char]
op fix name f = fix $ resOp name >> return f
res name f = resName name >> return f
instance IsString (Regex Char) where
fromString re = case parse (regex <* eof) "Regex" re of
Right r → r
Left err → error $ show errNow, we can finally complete the matches function.
{-# LANGUAGE OverloadedStrings, UnicodeSyntax #-}
module Text.Regex (matches) where
import Prelude.Unicode ((∘))
import Text.Regex.Core
import Text.Regex.DFA (accepts)
import Text.Regex.NFA (toDFA, toNFA, toNFAε)
import Text.Regex.Parser
-- | Synonym for regex strings
type Pattern = Regex Char
-- | Determines whether an input string
-- matches against a regular expression
matches ∷ String → Pattern → Bool
matches = flip $ accepts ∘ toDFA ∘ toNFA ∘ toNFAεNow let’s do some testing in the cabal repl.
Text.Regex> :set -XOverloadedStrings -- w.t. auto-call the regex parser
Text.Regex> "0110" `matches` "(0|(1(01*0)*1))*"
True
Text.Regex> "abc" `matches` "a|b*"
FalseIt works! Isn’t formal language theory great? You may ask, can this actually be used in a text processing project? No, turns out it slows to a crawl on longer expressions due to the series of automata conversions ¯\_(ツ)_/¯. I recommend a more mature, optimized alternative. I’ve put the source up on github.
P.S. A great exercise would be to write an algorithm that minimizes the generated DFA using the equivalence class construction to reduce the program’s memory footprint.